1
¡Estamos en la recta final! Tomemos un descanso de nuestro trabajo de superespía infiltrando hosts y echemos un vistazo al lado defensivo. Esta sección explora formas de detectar shells activos, buscar payloads en un host y en el tráfico de red, y cómo estos ataques pueden ser ofuscados para eludir nuestras defensas.
Monitoring
Cuando se trata de buscar e identificar shells activos, entrega y ejecución de payloads, e intentos potenciales de subvertir nuestras defensas, tenemos muchas opciones diferentes para detectar y responder a estos eventos. Antes de hablar sobre las fuentes de datos y herramientas que podemos usar, tomemos un segundo para hablar sobre el MITRE ATT&CK Framework y definir las técnicas y tácticas utilizadas por los atacantes. El ATT&CK Framework según MITRE, es "una base de conocimientos accesible globalmente de tácticas y técnicas de adversarios basada en observaciones del mundo real."
ATT&CK Framework

Teniendo en cuenta el framework, tres de las técnicas más notables que podemos vincular a Shells & Payloads se enumeran a continuación en la tabla con descripciones.
Notable MITRE ATT&CK Tactics and Techniques:
| Tactic / Technique | Description |
|---|---|
| Initial Access | Los atacantes intentarán obtener acceso inicial comprometiendo un host o servicio expuesto públicamente, como aplicaciones web, servicios mal configurados como SMB o protocolos de autenticación, y/o errores en un host expuesto públicamente que introducen una vulnerabilidad. Esto a menudo se hace en algún tipo de host bastión y proporciona al atacante un punto de apoyo en la red, pero aún no acceso completo. Para más información sobre acceso inicial, especialmente a través de aplicaciones web, consulta el OWASP Top Ten o lee más en el marco Mitre Att&ck. |
| Execution | Esta técnica depende de código suministrado e implantado por un atacante que se ejecuta en el host víctima. The Shells & Payloads se enfoca principalmente en esta táctica. Utilizamos muchos payloads diferentes, métodos de entrega y soluciones de scripting shell para acceder a un host. Esto puede ser cualquier cosa, desde la ejecución de comandos dentro de nuestro navegador web para obtener ejecución y acceso a una aplicación web, emitir una línea de comando de PowerShell a través de PsExec, aprovechar un exploit publicado públicamente o de día cero en conjunto con un framework como Metasploit, o cargar un archivo en un host a través de muchos protocolos diferentes y llamarlo remotamente para recibir una devolución. |
| Command & Control | Command and Control (C2) puede verse como la culminación de nuestros esfuerzos dentro de este módulo. Obtenemos acceso a un host y establecemos algún mecanismo para acceso continuo y/o interactivo a través de la ejecución de código, luego utilizamos ese acceso para realizar acciones de seguimiento en los objetivos dentro de la red víctima. El uso de puertos y protocolos estándar dentro de la red víctima para emitir comandos y recibir resultados es común. Esto puede aparecer como cualquier cosa, desde tráfico web normal a través de HTTP/S, comandos emitidos a través de otros protocolos externos comunes como DNS y NTP, e incluso el uso de aplicaciones comunes permitidas como Slack, Discord o MS Teams para emitir comandos y recibir check-ins. C2 puede tener varios niveles de sofisticación que van desde canales de texto claro básicos como Netcat hasta el uso de protocolos cifrados y ofuscados junto con rutas de tráfico complejas a través de proxies, redireccionadores y VPNs. |
Events To Watch For:
-
File uploads: Especialmente con aplicaciones web, las cargas de archivos son un método común para adquirir una shell en un host además de la ejecución directa de comandos en el navegador. Presta atención a los registros de la aplicación para determinar si alguien ha subido algo potencialmente malicioso. El uso de firewalls y antivirus puede agregar más capas a tu postura de seguridad alrededor del sitio. Cualquier host expuesto a internet desde tu red debe estar suficientemente reforzado y monitoreado. -
Suspicious non-admin user actions: Buscar cosas simples como usuarios normales emitiendo comandos a través de Bash o cmd puede ser un indicador significativo de compromiso. ¿Cuándo fue la última vez que un usuario promedio, mucho menos un administrador, tuvo que emitir el comandowhoamien un host? Los usuarios que se conectan a un recurso compartido en otro host en la red a través de SMB que no es un recurso compartido de infraestructura normal también pueden ser sospechosos. Este tipo de interacción generalmente es de host final a servidor de infraestructura, no de host final a host final. Habilitar medidas de seguridad como el registro de todas las interacciones de los usuarios, el registro de PowerShell y otras características que tomen nota cuando se utiliza una interfaz de shell te proporcionará más información. -
Anomalous network sessions: Los usuarios tienden a seguir un patrón para la interacción con la red. Visitan los mismos sitios web, usan las mismas aplicaciones y a menudo realizan esas acciones varias veces al día como un reloj. Registrar y analizar datos de NetFlow puede ser una excelente manera de detectar tráfico de red anómalo. Mirar cosas como los principales hablantes o visitas a sitios únicos, buscar un latido en un puerto no estándar (como el 4444, el puerto predeterminado utilizado por Meterpreter) y monitorear cualquier intento de inicio de sesión remoto o solicitudes masivas de GET / POST en cortos períodos de tiempo pueden ser indicadores de compromiso o intento de explotación. El uso de herramientas como monitores de red, registros de firewalls y SIEMS puede ayudar a dar un poco de orden al caos que es el tráfico de red.
Establish Network Visibility
Al igual que identificar y luego usar varios shells y payloads, detection y prevention requieren una comprensión detallada de los sistemas y el entorno de red general que estás tratando de proteger. Siempre es esencial tener buenas prácticas de documentación para que las personas responsables de mantener el entorno seguro puedan tener visibilidad constante de los dispositivos, datos y flujo de tráfico en los entornos que administran. Desarrollar y mantener diagramas de topología de red visuales puede ayudar a visualizar el flujo de tráfico de la red. Nuevas herramientas como netbrain pueden ser buenas para investigar, ya que combinan diagramas visuales que se pueden lograr con herramientas como Draw.io, documentación y gestión remota. Las topologías de red visuales interactivas te permiten interactuar con los routers, firewalls de red, dispositivos IDS/IPS, switches y hosts (clientes). Herramientas como estas se están volviendo más comunes de usar, ya que puede ser un desafío mantener la visibilidad de la red actualizada, especialmente en entornos más grandes que están en constante crecimiento.
Algunos proveedores de dispositivos de red como Cisco Meraki, Ubiquiti, Check Point y Palo Alto Networks están incorporando visibilidad de capa 7 (como la capa 7 del modelo OSI) en sus dispositivos de red y trasladando las capacidades de gestión a controladores de red basados en la nube. Esto significa que los administradores inician sesión en un portal web para gestionar todos los dispositivos de red en el entorno. A menudo se proporciona un tablero visual con estos controladores de red basados en la nube, lo que facilita tener una baseline del uso del tráfico, protocolos de red, aplicaciones y tráfico entrante y saliente. Tener y entender la línea base de tu red hará que cualquier desviación de la norma sea extremadamente visible. Cuanto más rápido puedas reaccionar y evaluar cualquier problema potencial, menos tiempo habrá para posibles fugas, destrucción de datos o algo peor.
Ten en cuenta que si un payload se ejecuta con éxito, necesitará comunicarse a través de la red, por lo que esta es la razón por la que la visibilidad de la red es esencial en el contexto de shells y payloads. Tener un dispositivo de seguridad de red capaz de deep packet inspection a menudo puede actuar como un antivirus para la red. Algunos de los payloads que discutimos podrían ser detectados y bloqueados a nivel de red si se ejecutan con éxito en los hosts. Esto es especialmente fácil de detectar si el tráfico no está cifrado. Cuando usamos Netcat en las secciones de bind y reverse shell, el tráfico que pasa entre la fuente y el destino (objetivo) no estaba cifrado. Alguien podría capturar ese tráfico y ver cada comando que enviamos entre nuestra caja de ataque y el objetivo, como se ve en los ejemplos a continuación.
Esta imagen muestra NetFlow entre dos hosts frecuentemente y en un puerto sospechoso (4444). Podemos decir que es tráfico TCP básico, por lo que si tomamos medidas e inspeccionamos un poco, podemos ver qué está sucediendo.
Suspicious Traffic.. In Clear Text
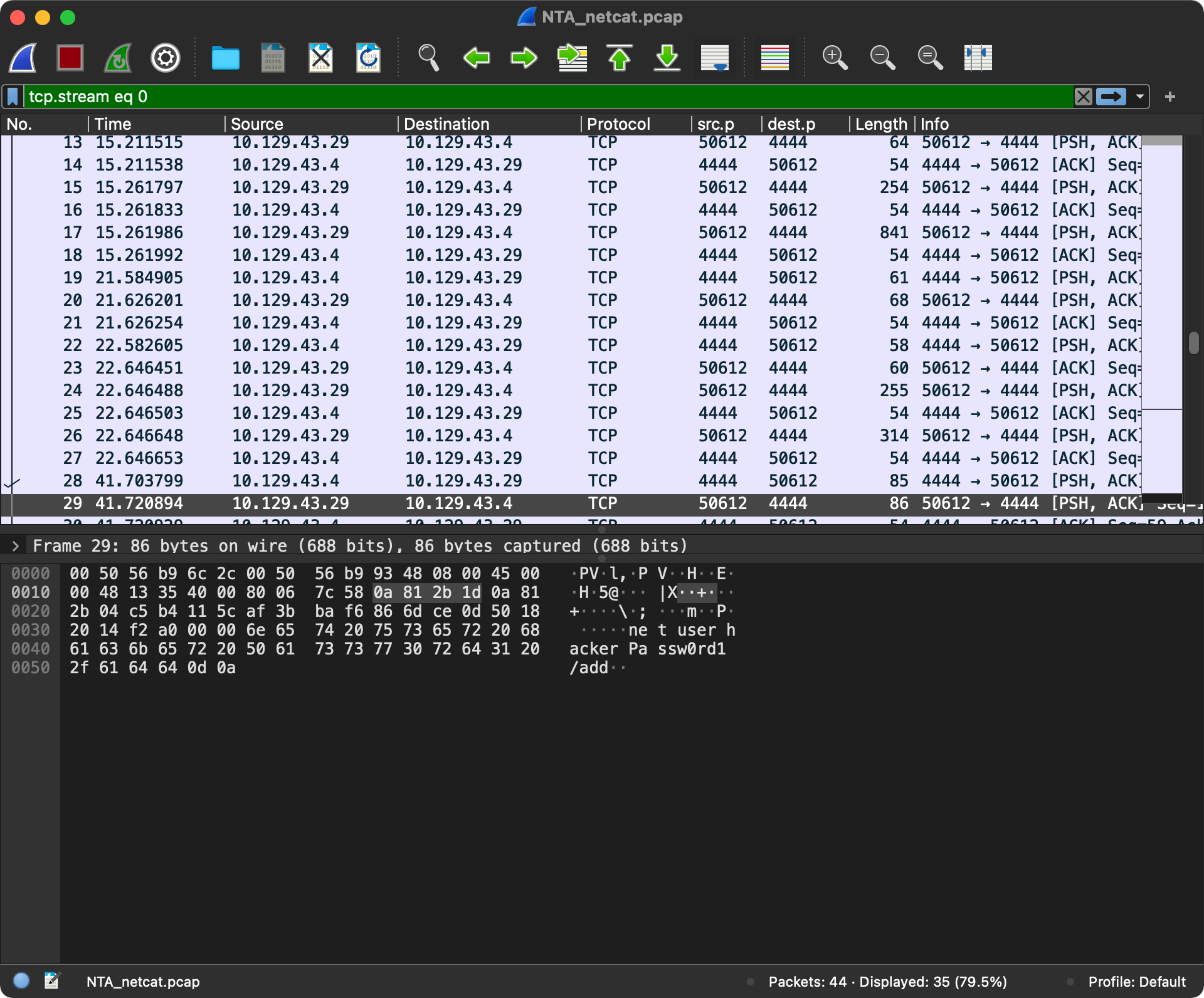
Observa ahora que ese mismo tráfico se ha expandido y podemos ver que alguien está usando net commands para crear un nuevo usuario en este host.
Following the Traffic
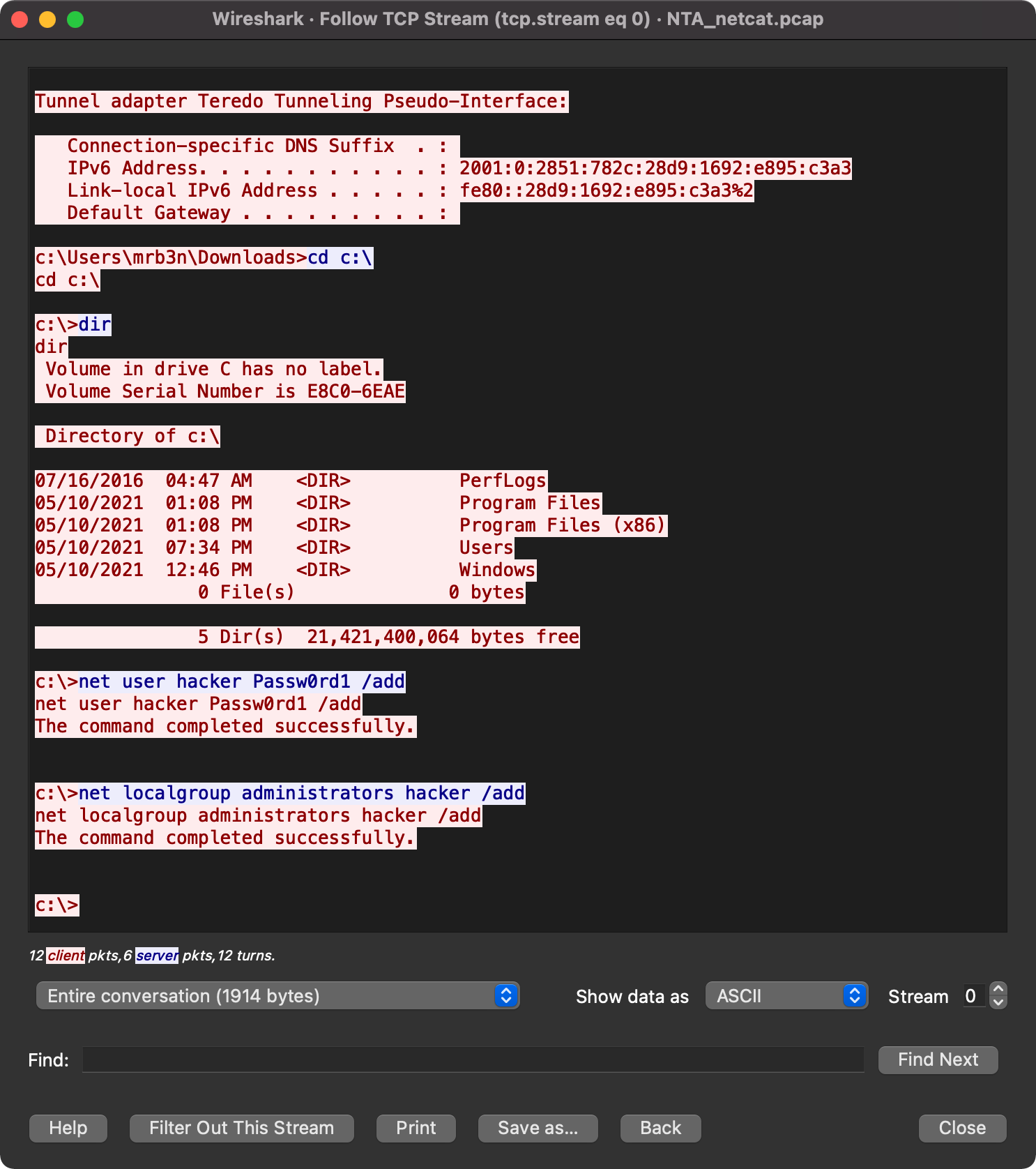
Este es un excelente ejemplo de acceso básico y ejecución de comandos para obtener persistencia mediante la adición de un usuario al host. Independientemente del nombre hacker que se esté utilizando, si el registro de la línea de comandos está en su lugar junto con los datos de NetFlow, podemos decir rápidamente que el usuario está realizando acciones potencialmente maliciosas y evaluar este evento para determinar si ha ocurrido un incidente o si es solo algún administrador jugando. Un dispositivo de seguridad moderno puede detectar, alertar y prevenir más comunicaciones de red desde ese host utilizando deep packet inspection.
Hablando de antivirus, hablemos un poco sobre la detección y protección de dispositivos finales.
Protecting End Devices
End devices son los dispositivos que se conectan al "final" de una red. Esto significa que son la fuente o el destino de la transmisión de datos. Algunos ejemplos de dispositivos finales serían:
- Estaciones de trabajo (computadoras de empleados)
- Servidores (proporcionando varios servicios en la red)
- Impresoras
- Network Attached Storage (NAS)
- Cámaras
- Smart TVs
- Smart Speakers
Debemos priorizar la protección de estos tipos de dispositivos, especialmente aquellos que ejecutan un sistema operativo con una CLI que puede ser accedida remotamente. La misma interfaz que facilita la administración y automatización de tareas en un dispositivo puede hacerlo un buen objetivo para los atacantes. Por simple que parezca, tener antivirus instalado y habilitado es un gran comienzo. El vector de ataque más común y exitoso además de la mala configuración es el elemento humano. Todo lo que se necesita es que un usuario haga clic en un enlace o abra un archivo, y pueden ser comprometidos. Tener monitoreo y alertas en tus dispositivos finales puede ayudar a detectar y potencialmente prevenir problemas antes de que ocurran.
En sistemas Windows, Windows Defender (también conocido como Windows Security o Microsoft Defender) está presente en la instalación y debe dejarse habilitado. Además, asegurarse de que el Firewall de Defender esté habilitado con todos los perfiles (Dominio, Privado y Público) activados. Solo hacer excepciones para aplicaciones aprobadas basadas en un change management process. Establecer una patch management estrategia (si no está ya establecida) para asegurar que todos los hosts reciban actualizaciones poco después de que Microsoft las libere. Todo esto se aplica a los servidores que alojan recursos compartidos y sitios web también. Aunque puede ralentizar el rendimiento, el antivirus en un servidor puede prevenir la ejecución de un payload y el establecimiento de una sesión shell con el sistema de un atacante malicioso.
Potential Mitigations:
Considera la siguiente lista cuando pienses en qué implementaciones puedes poner en práctica para mitigar muchos de estos vectores o exploits.
-
Application Sandboxing: Al sandboxear tus aplicaciones que están expuestas al mundo, puedes limitar el alcance del acceso y el daño que un atacante puede realizar si encuentra una vulnerabilidad o mala configuración en la aplicación. -
Least Privilege Permission Policies: Limitar los permisos que tienen los usuarios puede ayudar mucho a detener el acceso no autorizado o el compromiso. ¿Necesita un usuario ordinario acceso administrativo para realizar sus tareas diarias? ¿Qué pasa con el administrador de dominio? No realmente, ¿verdad? Asegurarse de que las políticas de seguridad y permisos adecuados estén en su lugar a menudo dificultará si no detendrá completamente un ataque. -
Host Segmentation & Hardening: Reforzar adecuadamente los hosts y segmentar cualquier host que requiera exposición a internet puede ayudar a asegurar que un atacante no pueda moverse lateralmente a tu red si obtiene acceso a un host límite. Seguir guías de reforzamiento STIG y colocar hosts como servidores web, servidores VPN, etc., en una DMZ o segmento de red 'cuarentena' detendrá ese tipo de acceso y movimiento lateral. -
Physical and Application Layer Firewalls: Los firewalls pueden ser herramientas poderosas si se implementan correctamente. Las reglas adecuadas de entrada y salida que solo permitan tráfico establecido primero desde dentro de tu red, en puertos aprobados para tus aplicaciones, y negando tráfico de entrada desde direcciones de red o espacio IP prohibido pueden paralizar muchas shells bind y reverse. Agrega un salto en la cadena de red, y las implementaciones de red como Network Address Translation (NAT) pueden romper la funcionalidad de un payload shell si no se tiene en cuenta.
Sum It All Up
Estas protecciones y mitigaciones no son el fin de todos los ataques. Se requiere una postura de seguridad y una estrategia de defensa sólidas en la era actual. Adaptar un enfoque de defensa en profundidad a tu postura de seguridad ayudará a dificultar a los atacantes y asegurará que los objetivos fáciles no puedan ser aprovechados fácilmente.