1
A medida que aprendemos varias instrucciones de Assembly en las próximas secciones, estaremos constantemente escribiendo código, ensamblándolo y depurándolo. Esta es la mejor manera de aprender lo que hace cada instrucción. Por lo tanto, necesitamos aprender la estructura básica de un archivo de código Assembly y luego ensamblarlo y depurarlo.
En esta sección, revisaremos la estructura básica de un archivo Assembly, y en las dos secciones siguientes, cubriremos cómo ensamblarlo y depurarlo. Trabajaremos con una plantilla de código Assembly llamada Hello World! como ejemplo, para aprender primero la estructura general de un archivo Assembly y luego cómo ensamblarlo y depurarlo. Comencemos analizando una plantilla de código Assembly de ejemplo Hello World!:
global _start
section .data
message: db "Hello HTB Academy!"
section .text
_start:
mov rax, 1
mov rdi, 1
mov rsi, message
mov rdx, 18
syscall
mov rax, 60
mov rdi, 0
syscall
Este código Assembly (una vez ensamblado y enlazado) debería imprimir la cadena 'Hello HTB Academy!' en la pantalla. No entraremos en detalles sobre cómo se procesa esto todavía, pero necesitamos entender los elementos principales de la plantilla de código.
Assembly File Structure
Primero, examinemos cómo está distribuido el código:
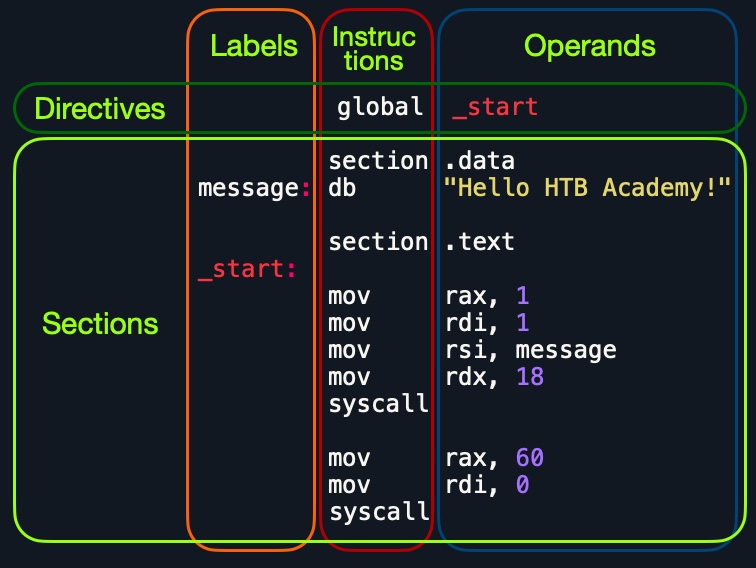
Al observar las partes verticales del código, cada línea puede tener tres elementos:
1. Labels |
2. Instructions |
3. Operands |
|---|---|---|
Hemos discutido las instructions y sus operands en las secciones anteriores, y entraremos en detalle sobre varias instrucciones de Assembly en las próximas secciones. Además de eso, podemos definir un label en cada línea. Cada label puede ser referido por instructions o por directives.
A continuación, si miramos el código línea por línea, vemos que tiene tres partes principales:
| Section | Description |
|---|---|
global _start |
Esta es una directive que dirige el código para comenzar a ejecutarse en el label _start definido más abajo. |
section .data |
Esta es la sección de data, que debe contener todas las variables. |
section .text |
Esta es la sección de text que contiene todo el código que se ejecutará. |
Tanto las secciones .data como .text se refieren a los segmentos de memoria data y text, en los que se almacenarán estas instrucciones.
Directives
Un código Assembly es basado en líneas, lo que significa que el archivo se procesa línea por línea, ejecutando la instrucción de cada línea. Vemos en la primera línea una directiva global _start, que instruye a la máquina para comenzar a procesar las instrucciones después del label _start. Así, la máquina va al label _start y comienza a ejecutar las instrucciones allí, lo que imprimirá el mensaje en la pantalla. Esto se cubrirá más a fondo en las secciones de Control Instructions.
Variables
A continuación, tenemos la sección .data. La sección de data contiene nuestras variables para facilitar la definición y reutilización de estas sin escribirlas varias veces. Una vez que ejecutamos nuestro programa, todas nuestras variables se cargarán en memoria en el segmento de data.
Cuando ejecutamos el programa, cargará cualquier variable que hayamos definido en memoria para que estén listas para su uso cuando las llamemos. Notaremos más adelante en el módulo que para el momento en que comencemos a ejecutar instrucciones en el label _start, todas nuestras variables ya estarán cargadas en memoria.
Podemos definir variables usando db para una lista de bytes, dw para una lista de palabras, dd para una lista de dígitos, y así sucesivamente. También podemos etiquetar cualquiera de nuestras variables para poder llamarla o referenciarla más tarde. A continuación, algunos ejemplos de definición de variables:
| Instruction | Description |
|---|---|
db 0x0a |
Define el byte 0x0a, que es una nueva línea. |
message db 0x41, 0x42, 0x43, 0x0a |
Define el label message => abc\n. |
message db "Hello World!", 0x0a |
Define el label message => Hello World!\n. |
Además, podemos usar la instrucción equ con el token $ para evaluar una expresión, como la longitud de la cadena de una variable definida. Sin embargo, los labels definidos con la instrucción equ son constantes y no se pueden cambiar más tarde.
Por ejemplo, el siguiente código define una variable y luego define una constante para su longitud:
section .data
message db "Hello World!", 0x0a
length equ $-message
Nota: el token $ indica la distancia actual desde el inicio de la sección actual. Como la variable message está al comienzo de la sección data, la ubicación actual, es decir, el valor de $, equivale a la longitud de la cadena. Para el alcance de este módulo, solo usaremos este token para calcular longitudes de cadenas, usando la misma línea de código mostrada arriba.
Code
La segunda (y más importante) sección es la sección .text. Esta sección contiene todas las instrucciones de Assembly y las carga en el segmento de memoria text. Una vez que todas las instrucciones se cargan en el segmento text, el procesador comienza a ejecutarlas una tras otra.
La convención predeterminada es tener el label _start al comienzo de la sección .text, que -según la directiva global _start- inicia el código principal que se ejecutará a medida que el programa se ejecute. Como veremos más adelante en el módulo, podemos definir otros labels dentro de la sección .text, para bucles y otras funciones.
El segmento text dentro de la memoria es de solo lectura, por lo que no podemos escribir ninguna variable dentro de él. La sección data, por otro lado, es de lectura/escritura, por lo que escribimos nuestras variables en ella. Sin embargo, el segmento data dentro de la memoria no es ejecutable, por lo que cualquier código que escribamos en él no puede ser ejecutado. Esta separación es parte de las protecciones de memoria para mitigar cosas como buffer overflows y otros tipos de explotación binaria.
Tip: Podemos agregar comentarios a nuestro código Assembly con un punto y coma ;. Podemos usar comentarios para explicar el propósito de cada parte del código y qué hace cada línea. Hacer esto nos ahorrará mucho tiempo en el futuro si alguna vez volvemos a revisar el código y necesitamos entenderlo.
Con esto, deberíamos entender la estructura básica de un archivo Assembly.